Notes from "Fundamentals of Data Engineering": Designing Good Data Architecture
My Notes from Chapter 3 of Fundamentals of Data Engineering


Good data architecture provides seamless capabilities across every step of the data lifecycle and undercurrent.
What is Data Architecture?
Successful data engineering is built upon rock-solid data architecture. Researching data architecture yields many inconsistent and often outdated definitions.
Enterprise Architecture Defined
Enterprise architecture has many subsets, including business, technical, application, and data.

Enterprise architecture is the design of systems to support change in the enterprise, achieved by flexible and reversible decisions reached through careful evaluation of trade-offs.
Flexible and reversible decisions are essential for two reasons. First, the world is constantly changing, and predicting the future is impossible. Reversible decisions allow you to adjust course as the world changes and you gather new information. Second, there is a natural tendency toward enterprise ossification as organizations grow. Adopting a culture of reversible decisions helps overcome this tendency by reducing the risk attached to a decision. Jeff Bezos is credited with the idea of one-way and two-way doors.4 A one-way door is a decision that is almost impossible to reverse. For example, Amazon could have decided to sell AWS or shut it down. It would be nearly impossible for Amazon to rebuild a public cloud with the same market position after such an action. On the other hand, a two-way door is an easily reversible decision: you walk through and proceed if you like what you see in the room or step back through the door if you don’t.
Change management is closely related to reversible decisions and is a central theme of enterprise architecture frameworks. Even with an emphasis on reversible decisions, enterprises often need to undertake large initiatives. These are ideally broken into smaller changes, each one a reversible decision in itself.
Architects identify problems in the current state (poor data quality, scalability limits, money-losing lines of business), define desired future states (agile data-quality improvement, scalable cloud data solutions, improved business processes), and realize initiatives through execution of small, concrete steps. It bears repeating:
Technical solutions exist not for their own sake but in support of business goals.
Enterprise architecture balances flexibility and trade-offs.
Data Architecture Defined
Data architecture is the design of systems to support the evolving data needs of an enterprise, achieved by flexible and reversible decisions reached through a careful evaluation of trade-offs. Just as the data engineering lifecycle is a subset of the data lifecycle, data engineering architecture is a subset of general data architecture. Data engineering architecture is the systems and frameworks that make up the key sections of the data engineering lifecycle. We’ll use data architecture interchangeably with data engineering architecture.
Operational architecture encompasses the functional requirements of what needs to happen related to people, processes, and technology.
Technical architecture outlines how data is ingested, stored, transformed, and served along the data engineering lifecycle.

"Good" Data Architecture
Good data architecture serves business requirements with a common, widely reusable set of building blocks while maintaining flexibility and making appropriate trade-offs. Bad architecture is authoritarian and tries to cram a bunch of one-size-fits-all decisions into a big ball of mud.
Agility is the foundation for good data architecture; it acknowledges that the world is fluid. Good data architecture is flexible and easily maintainable. It evolves in response to changes within the business and new technologies and practices that may unlock even more value in the future.
Bad data architecture is tightly coupled, rigid, overly centralized, or uses the wrong tools for the job, hampering development and change management.
Principles of Good Data Architecture
The AWS Well-Architected Framework consists of six pillars:
- Operational excellence
- Security
- Reliability
- Performance efficiency
- Cost optimization
- Sustainability
Google Cloud’s Five Principles for Cloud-Native Architecture are as follows:
- Design for automation.
- Be smart with state.
- Favor managed services.
- Practice defense in depth.
- Always be architecting.
We’d like to expand or elaborate on these pillars with these principles of data engineering architecture:
- Choose common components wisely.
- Plan for failure.
- Architect for scalability.
- Architecture is leadership.
- Always be architecting.
- Build loosely coupled systems.
- Make reversible decisions.
- Prioritize security.
- Embrace FinOps.
Principle 1: Choose Common Components Wisely
When architects choose well and lead effectively, common components become a fabric facilitating team collaboration and breaking down silos. Common components enable agility within and across teams in conjunction with shared knowledge and skills. Common components can be anything that has broad applicability within an organization. Common components include object storage, version-control systems, observability, monitoring and orchestration systems, and processing engines. Cloud platforms are an ideal place to adopt common components.
Principle 2: Plan for Failure
Here are a few key terms for evaluating failure scenarios; we describe these in greater detail in this chapter and throughout the book:
- Availability - The percentage of time an IT service or component is in an operable state.
- Reliability - The system’s probability of meeting defined standards in performing its intended function during a specified interval.
- Recovery time objective - The maximum acceptable time for a service or system outage. The recovery time objective (RTO) is generally set by determining the business impact of an outage. An RTO of one day might be fine for an internal reporting system. A website outage of just five minutes could have a significant adverse business impact on an online retailer.
- Recovery point objective - The acceptable state after recovery. In data systems, data is often lost during an outage. In this setting, the recovery point objective (RPO) refers to the maximum acceptable data loss.
Principle 3: Architect for Scalability
Scalability in data systems encompasses two main capabilities. First, scalable systems can scale up to handle significant quantities of data. Second, scalable systems can scale down. Once the load spike ebbs, we should automatically remove capacity to cut costs. (This is related to principle 9. EMbrace FinOps) An elastic system can scale dynamically in response to load, ideally in an automated fashion.
Principle 4: Architecture is Leadership
Data architects are responsible for technology decisions and architecture descriptions and disseminating these choices through effective leadership and training. Data architects should be highly technically competent but delegate most individual contributor work to others.
An ideal data architect manifests similar characteristics. They possess the technical skills of a data engineer but no longer practice data engineering day to day; they mentor current data engineers, make careful technology choices in consultation with their organization, and disseminate expertise through training and leadership. They train engineers in best practices and bring the company’s engineering resources together to pursue common goals in both technology and business.
Principle 5: Always Be Architecting
An architect’s job is to develop deep knowledge of the baseline architecture (current state), develop a target architecture, and map out a sequencing plan to determine priorities and the order of architecture changes.
Principle 6: Build Loosely Coupled Systems
When the architecture of the system is designed to enable teams to test, deploy, and change systems without dependencies on other teams, teams require little communication to get work done. In other words, both the architecture and the teams are loosely coupled.
For software architecture, a loosely coupled system has the following properties:
- Systems are broken into many small components.
- These systems interface with other services through abstraction layers, such as a messaging bus or an API. These abstraction layers hide and protect internal details of the service, such as a database backend or internal classes and method calls.
- As a consequence of property 2, internal changes to a system component don’t require changes in other parts. Details of code updates are hidden behind stable APIs. Each piece can evolve and improve separately.
- As a consequence of property 3, there is no waterfall, global release cycle for the whole system. Instead, each component is updated separately as changes and improvements are made.
Principle 7: Make Reversible Decisions
Given the pace of change—and the decoupling/modularization of technologies across your data architecture—always strive to pick the best-of-breed solutions that work for today. Also, be prepared to upgrade or adopt better practices as the landscape evolves.
Principle 8: Prioritize Security
Every data engineer must assume responsibility for the security of the systems they build and maintain. We focus now on two main ideas: zero-trust security and the shared responsibility security model. These align closely to a cloud-native architecture.
Principle 9: Embrace FinOps
FinOps is an evolving cloud financial management discipline and cultural practice that enables organizations to get maximum business value by helping engineering, finance, technology, and business teams to collaborate on data-driven spending decisions.
In the past, data engineers thought in terms of performance engineering—maximizing the performance for data processes on a fixed set of resources and buying adequate resources for future needs. With FinOps, engineers need to learn to think about the cost structures of cloud systems. For example, what is the appropriate mix of AWS spot instances when running a distributed cluster? What is the most appropriate approach for running a sizable daily job in terms of cost-effectiveness and performance? When should the company switch from a pay-per-query model to reserved capacity?
Major Architecture Concepts
We must not lose sight of the main goal of all of these architectures: to take data and transform it into something useful for downstream consumption.
Domains and Services
A domain is the real-world subject area for which you’re architecting. A service is a set of functionality whose goal is to accomplish a task.
A domain can contain multiple services. For example, you might have a sales domain with three services: orders, invoicing, and products. Each service has particular tasks that support the sales domain. Other domains may also share services.
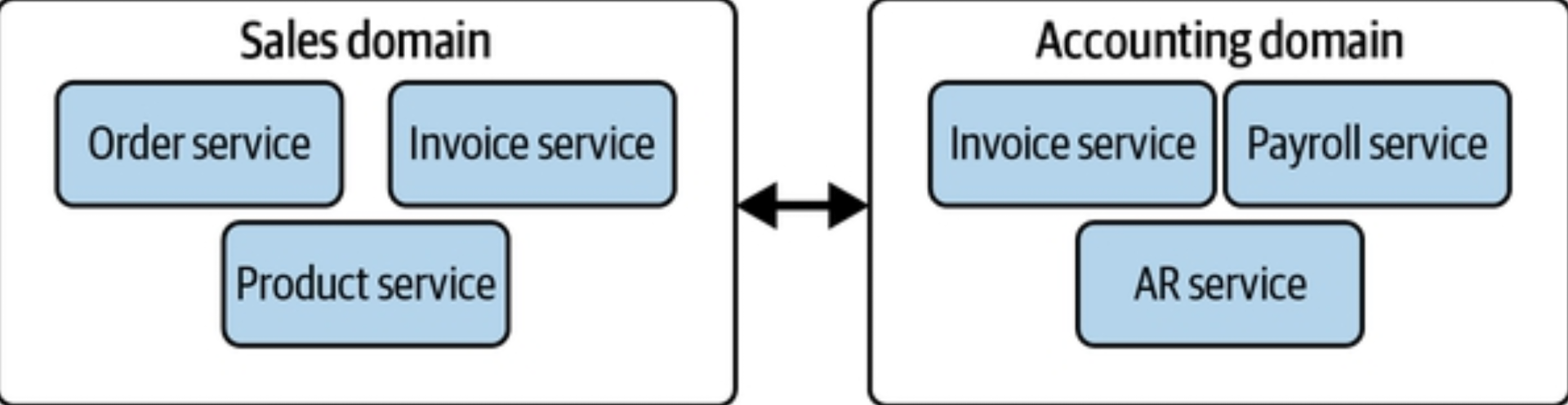
When thinking about what constitutes a domain, focus on what the domain represents in the real world and work backward.
Distributed Systems, Scalability, and Designing for Failure
As data engineers, we’re interested in four closely related characteristics of data systems (availability and reliability were mentioned previously, but we reiterate them here for completeness):
- Scalability - Allows us to increase the capacity of a system to improve performance and handle the demand. For example, we might want to scale a system to handle a high rate of queries or process a huge data set.
- Elasticity - The ability of a scalable system to scale dynamically; a highly elastic system can automatically scale up and down based on the current workload. Scaling up is critical as demand increases, while scaling down saves money in a cloud environment. Modern systems sometimes scale to zero, meaning they can automatically shut down when idle.
- Availability The percentage of time an IT service or component is in an operable state.
- Reliability The system’s probability of meeting defined standards in performing its intended function during a specified interval.
Distributed systems are widespread in the various data technologies you’ll use across your architecture. Almost every cloud data warehouse object storage system you use has some notion of distribution under the hood.
Tight vs Loose Coupling: Tiers, Monoliths, and Microservices
On one end of the spectrum, you can choose to have extremely centralized dependencies and workflows. Every part of a domain and service is vitally dependent upon every other domain and service. This pattern is known as tightly coupled.
On the other end of the spectrum, you have decentralized domains and services that do not have strict dependence on each other, in a pattern known as loose coupling. In a loosely coupled scenario, it’s easy for decentralized teams to build systems whose data may not be usable by their peers.
Architecture Tiers
As you develop your architecture, it helps to be aware of architecture tiers. Your architecture has layers—data, application, business logic, presentation, and so forth—and you need to know how to decouple these layers. Because tight coupling of modalities presents obvious vulnerabilities, keep in mind how you structure the layers of your architecture to achieve maximum reliability and flexibility.
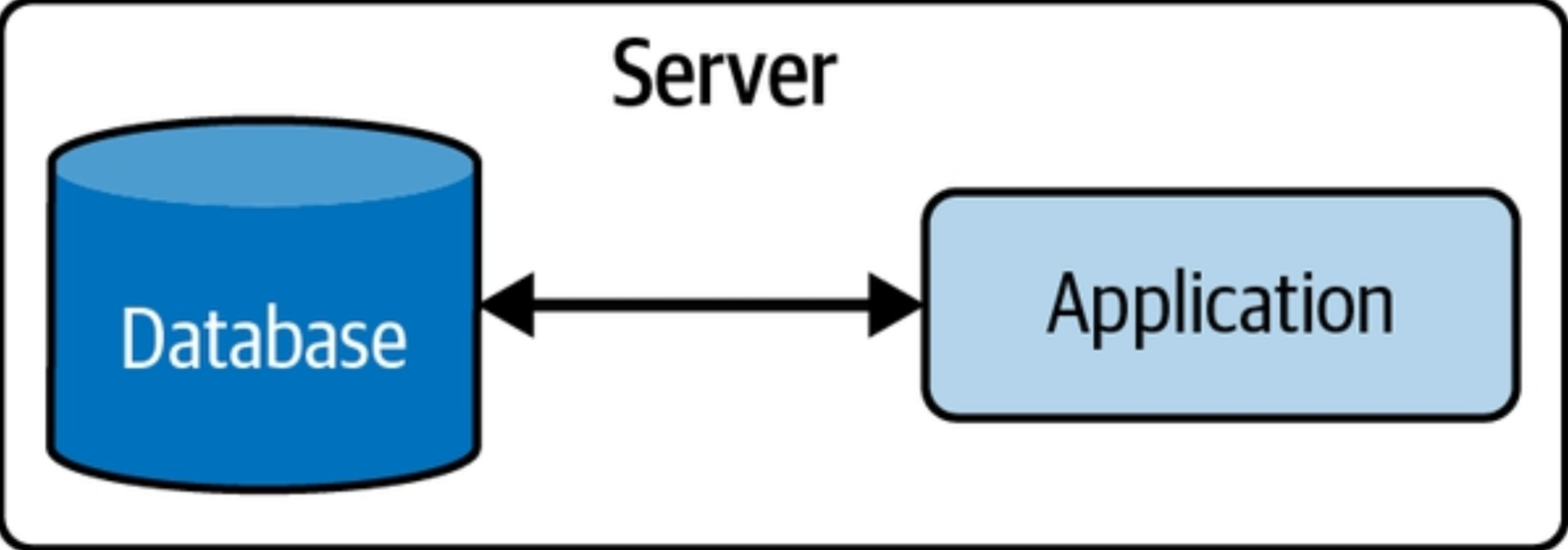
Single Tier
In a single-tier architecture, your database and application are tightly coupled, residing on a single server.
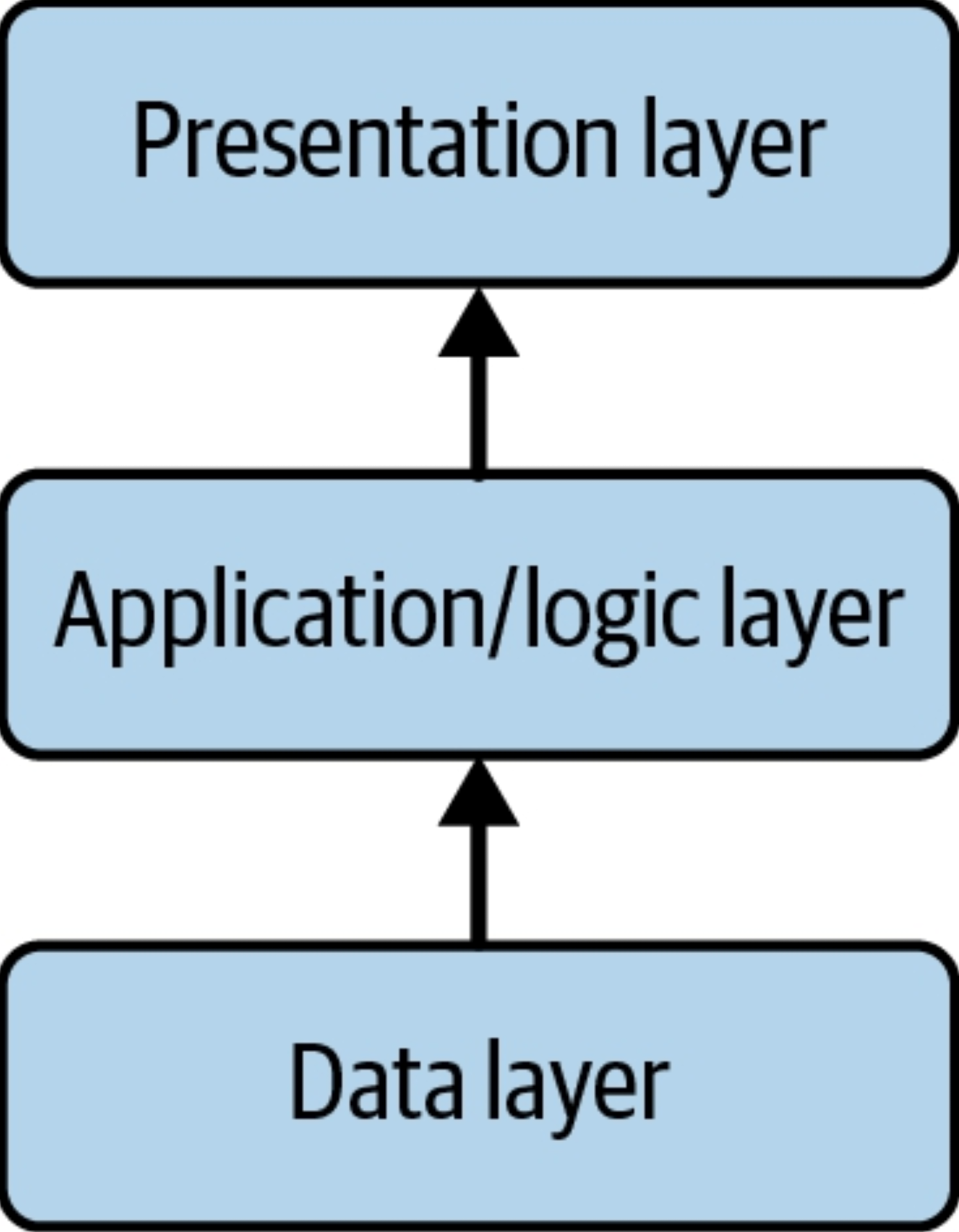
Multitier
A multitier (also known as n-tier) architecture is composed of separate layers: data, application, business logic, presentation, etc. These layers are bottom-up and hierarchical, meaning the lower layer isn’t necessarily dependent on the upper layers; the upper layers depend on the lower layers. The notion is to separate data from the application, and application from the presentation.
A common multitier architecture is a three-tier architecture, a widely used client-server design. A three-tier architecture consists of data, application logic, and presentation tiers.
Monoliths
Coupling within monoliths can be viewed in two ways: technical coupling and domain coupling. Technical coupling refers to architectural tiers, while domain coupling refers to the way domains are coupled together. A monolith has varying degrees of coupling among technologies and domains. You could have an application with various layers decoupled in a multitier architecture but still share multiple domains.
Microservices
Microservices architecture comprises separate, decentralized, and loosely coupled services. Each service has a specific function and is decoupled from other services operating within its domain. If one service temporarily goes down, it won’t affect the ability of other services to continue functioning.
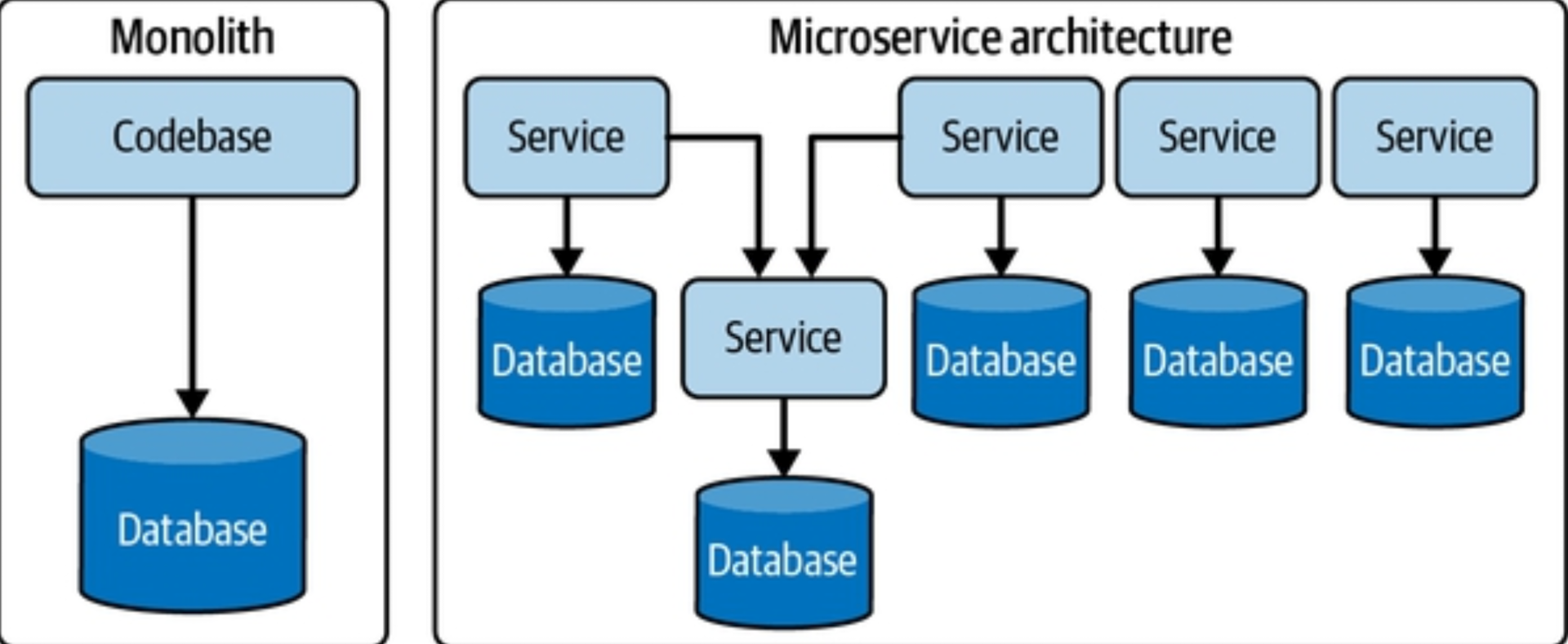
Considerations for Data Architecture
Rather than dogmatically preach microservices over monoliths (among other arguments), we suggest you pragmatically use loose coupling as an ideal, while recognizing the state and limitations of the data technologies you’re using within your data architecture. Incorporate reversible technology choices that allow for modularity and loose coupling whenever possible.
One approach to this problem is centralization: a single team is responsible for gathering data from all domains and reconciling it for consumption across the organization. (This is a common approach in traditional data warehousing.) Another approach is the data mesh. With the data mesh, each software team is responsible for preparing its data for consumption across the rest of the organization.
User Access: Single vs Multitenant
We have two factors to consider in multitenancy: performance and security. With multiple large tenants within a cloud system, will the system support consistent performance for all tenants, or will there be a noisy neighbor problem? (That is, will high usage from one tenant degrade performance for other tenants?) Regarding security, data from different tenants must be properly isolated.
Event-Driven Architecture
Your business is rarely static. Things often happen in your business, such as getting a new customer, a new order from a customer, or an order for a product or service. These are all examples of events that are broadly defined as something that happened, typically a change in the state of something. An event-driven workflow encompasses the ability to create, update, and asynchronously move events across various parts of the data engineering lifecycle. This workflow boils down to three main areas: event production, routing, and consumption.

An event-driven architecture embraces the event-driven workflow and uses this to communicate across various services. The advantage of an event-driven architecture is that it distributes the state of an event across multiple services.

Brownfield vs Greenfield Projects
Before you design your data architecture project, you need to know whether you’re starting with a clean slate or redesigning an existing architecture.
Brownfield Projects
Brownfield projects often involve refactoring and reorganizing an existing architecture and are constrained by the choices of the present and past. Because a key part of architecture is change management, you must figure out a way around these limitations and design a path forward to achieve your new business and technical objectives. Brownfield projects require a thorough understanding of the legacy architecture and the interplay of various old and new technologies.
Greenfield Projects
On the opposite end of the spectrum, a greenfield project allows you to pioneer a fresh start, unconstrained by the history or legacy of a prior architecture. Greenfield projects tend to be easier than brownfield projects, and many data architects and engineers find them more fun!
Examples and Types of Data Architecture
Because data architecture is an abstract discipline, it helps to reason by example. In this section, we outline prominent examples and types of data architecture that are popular today.
Data Warehouse
A data warehouse is a central data hub used for reporting and analysis. Data in a data warehouse is typically highly formatted and structured for analytics use cases. It’s among the oldest and most well-established data architectures.
It’s worth noting two types of data warehouse architecture: organizational and technical. The organizational data warehouse architecture organizes data associated with certain business team structures and processes. The technical data warehouse architecture reflects the technical nature of the data warehouse, such as MPP.
The organizational data warehouse architecture has two main characteristics:
- Separates online analytical processing (OLAP) from production databases (online transaction processing) - This separation is critical as businesses grow. Moving data into a separate physical system directs load away from production systems and improves analytics performance.
- Centralizes and organizes data Traditionally, a data warehouse pulls data from application systems by using ETL. The extract phase pulls data from source systems.
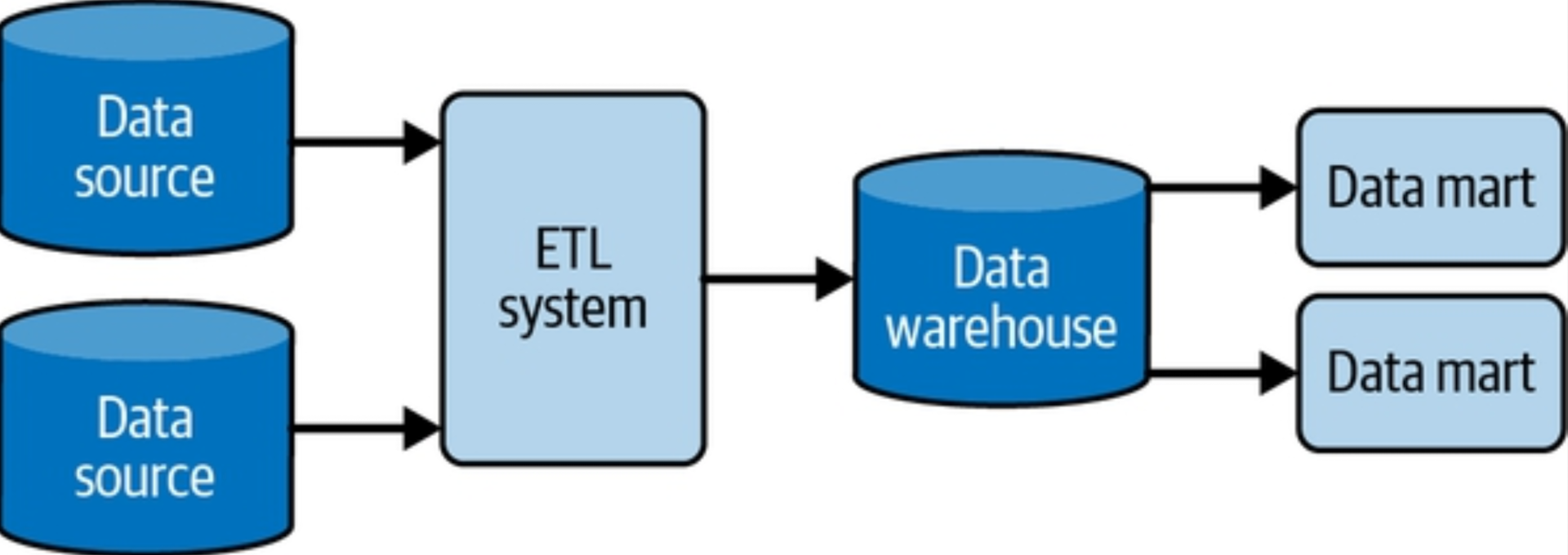
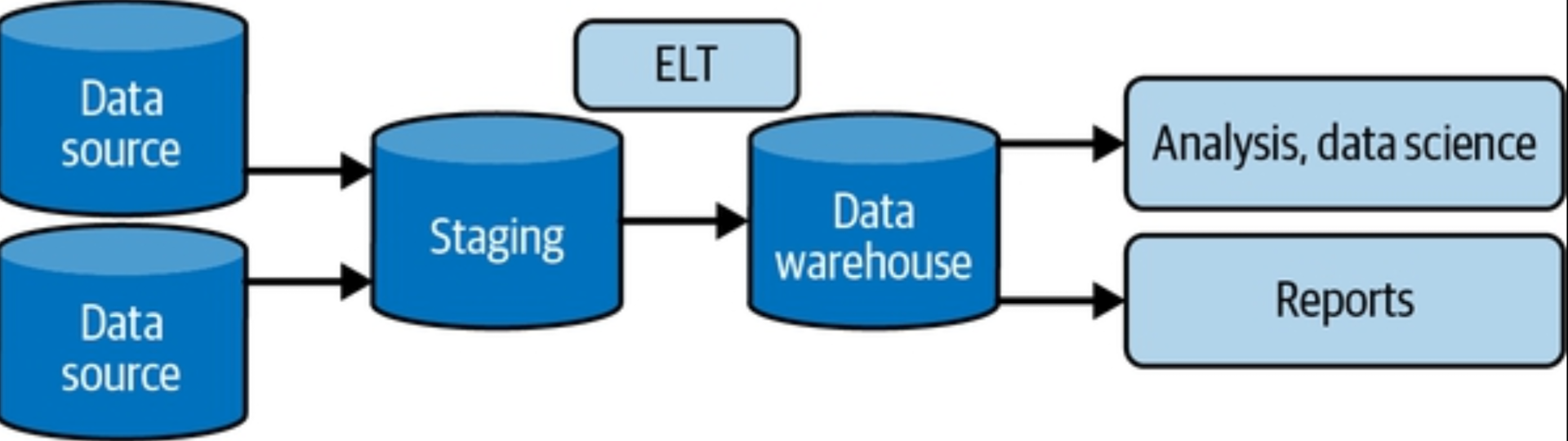
One variation on ETL is ELT. With the ELT data warehouse architecture, data gets moved more or less directly from production systems into a staging area in the data warehouse. Staging in this setting indicates that the data is in a raw form. Rather than using an external system, transformations are handled directly in the data warehouse. The intention is to take advantage of the massive computational power of cloud data warehouses and data processing tools.
The Cloud Data Warehouse
Cloud data warehouses represent a significant evolution of the on-premises data warehouse architecture and have thus led to significant changes to the organizational architecture. Amazon Redshift kicked off the cloud data warehouse revolution.
Data Marts
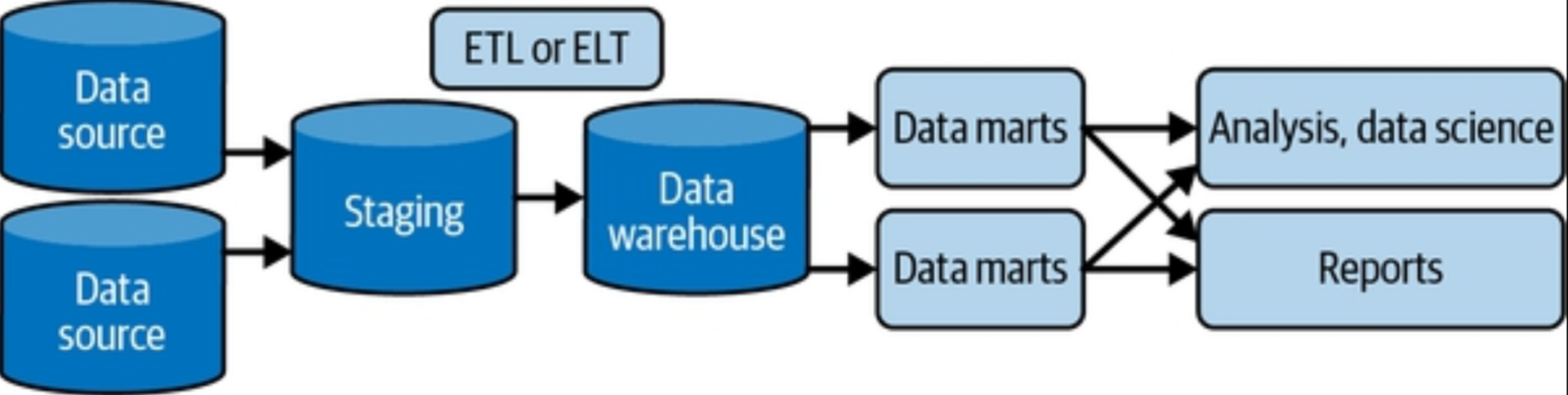
A data mart is a more refined subset of a warehouse designed to serve analytics and reporting, focused on a single suborganization, department, or line of business; every department has its own data mart, specific to its needs. Data marts exist for two reasons. First, a data mart makes data more easily accessible to analysts and report developers. Second, data marts provide an additional stage of transformation beyond that provided by the initial ETL or ELT pipelines.
Data Lake
Among the most popular architectures that appeared during the big data era is the data lake. Instead of imposing tight structural limitations on data, why not simply dump all of your data—structured and unstructured—into a central location? The data lake promised to be a democratizing force, liberating the business to drink from a fountain of limitless data.
The data lake became a dumping ground; terms such as data swamp, dark data, and WORN were coined as once-promising data projects failed. Data grew to unmanageable sizes, with little in the way of schema management, data cataloging, and discovery tools. Many organizations found significant value in data lakes—especially huge, heavily data-focused Silicon Valley tech companies like Netflix and Facebook.
Convergence, Next-Generation Data Lakes, and the Data Platform
In response to the limitations of first-generation data lakes, various players have sought to enhance the concept to fully realize its promise. For example, Databricks introduced the notion of a data lakehouse. The lakehouse incorporates the controls, data management, and data structures found in a data warehouse while still housing data in object storage and supporting a variety of query and transformation engines. In particular, the data lakehouse supports atomicity, consistency, isolation, and durability (ACID) transactions, a big departure from the original data lake, where you simply pour in data and never update or delete it. The term data lakehouse suggests a convergence between data lakes and data warehouses.
Modern Data Stack
The modern data stack is currently a trendy analytics architecture that highlights the type of abstraction we expect to see more widely used over the next several years. Whereas past data stacks relied on expensive, monolithic toolsets, the main objective of the modern data stack is to use cloud-based, plug-and-play, easy-to-use, off-the-shelf components to create a modular and cost-effective data architecture. These components include data pipelines, storage, transformation, data management/governance, monitoring, visualization, and exploration.

Lambda Architecture
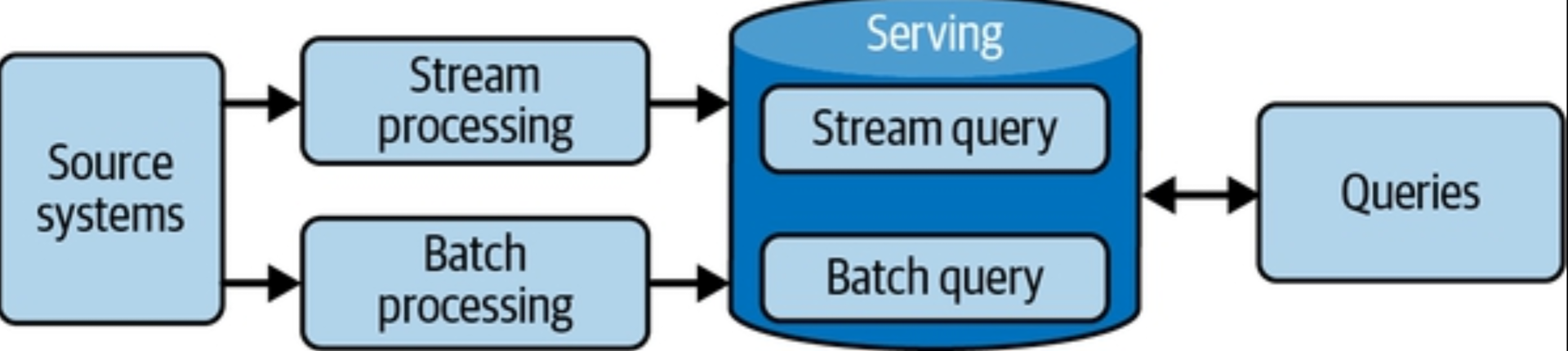
In a Lambda architecture, you have systems operating independently of each other—batch, streaming, and serving. The source system is ideally immutable and append-only, sending data to two destinations for processing: stream and batch. In-stream processing intends to serve the data with the lowest possible latency in a “speed” layer, usually a NoSQL database. In the batch layer, data is processed and transformed in a system such as a data warehouse, creating precomputed and aggregated views of the data. The serving layer provides a combined view by aggregating query results from the two layers.
Kappa Architecture
As a response to the shortcomings of Lambda architecture, Jay Kreps proposed an alternative called Kappa architecture. The central thesis is this: why not just use a stream-processing platform as the backbone for all data handling—ingestion, storage, and serving? This facilitates a true event-based architecture. Real-time and batch processing can be applied seamlessly to the same data by reading the live event stream directly and replaying large chunks of data for batch processing.

Though the original Kappa architecture article came out in 2014, we haven’t seen it widely adopted. There may be a couple of reasons for this. First, streaming itself is still a bit of a mystery for many companies; it’s easy to talk about, but harder than expected to execute. Second, Kappa architecture turns out to be complicated and expensive in practice.
The Dataflow Model and Unified Batch and Streaming
The core idea in the Dataflow model is to view all data as events, as the aggregation is performed over various types of windows. Ongoing real-time event streams are unbounded data. Data batches are simply bounded event streams, and the boundaries provide a natural window. Engineers can choose from various windows for real-time aggregation, such as sliding or tumbling. Real-time and batch processing happens in the same system using nearly identical code.
Architecture for IoT
The Internet of Things (IoT) is the distributed collection of devices, aka things—computers, sensors, mobile devices, smart home devices, and anything else with an internet connection. Rather than generating data from direct human input (think data entry from a keyboard), IoT data is generated from devices that collect data periodically or continuously from the surrounding environment and transmit it to a destination.
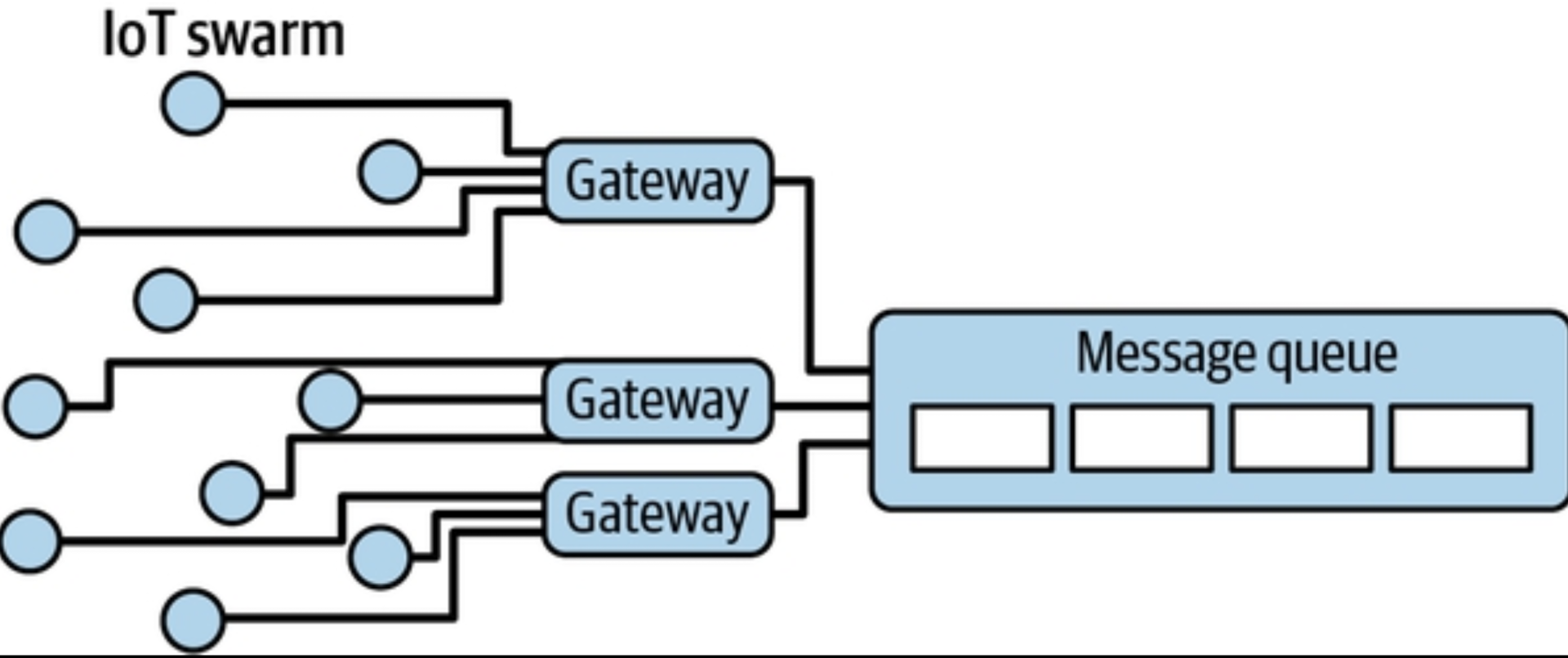
- Devices - Devices (also known as things) are the physical hardware connected to the internet, sensing the environment around them and collecting and transmitting data to a downstream destination.
- Interfacing with Devices - An IoT gateway is a hub for connecting devices and securely routing devices to the appropriate destinations on the internet. While you can connect a device directly to the internet without an IoT gateway, the gateway allows devices to connect using extremely little power.
- Ingestion - Ingestion begins with an IoT gateway, as discussed previously. From there, events and measurements can flow into an event ingestion architecture.
- Storage - Storage requirements will depend a great deal on the latency requirement for the IoT devices in the system.
- Serving - Serving patterns are incredibly diverse. In a batch scientific application, data might be analyzed using a cloud data warehouse and then served in a report. Data will be presented and served in numerous ways in a home-monitoring application.

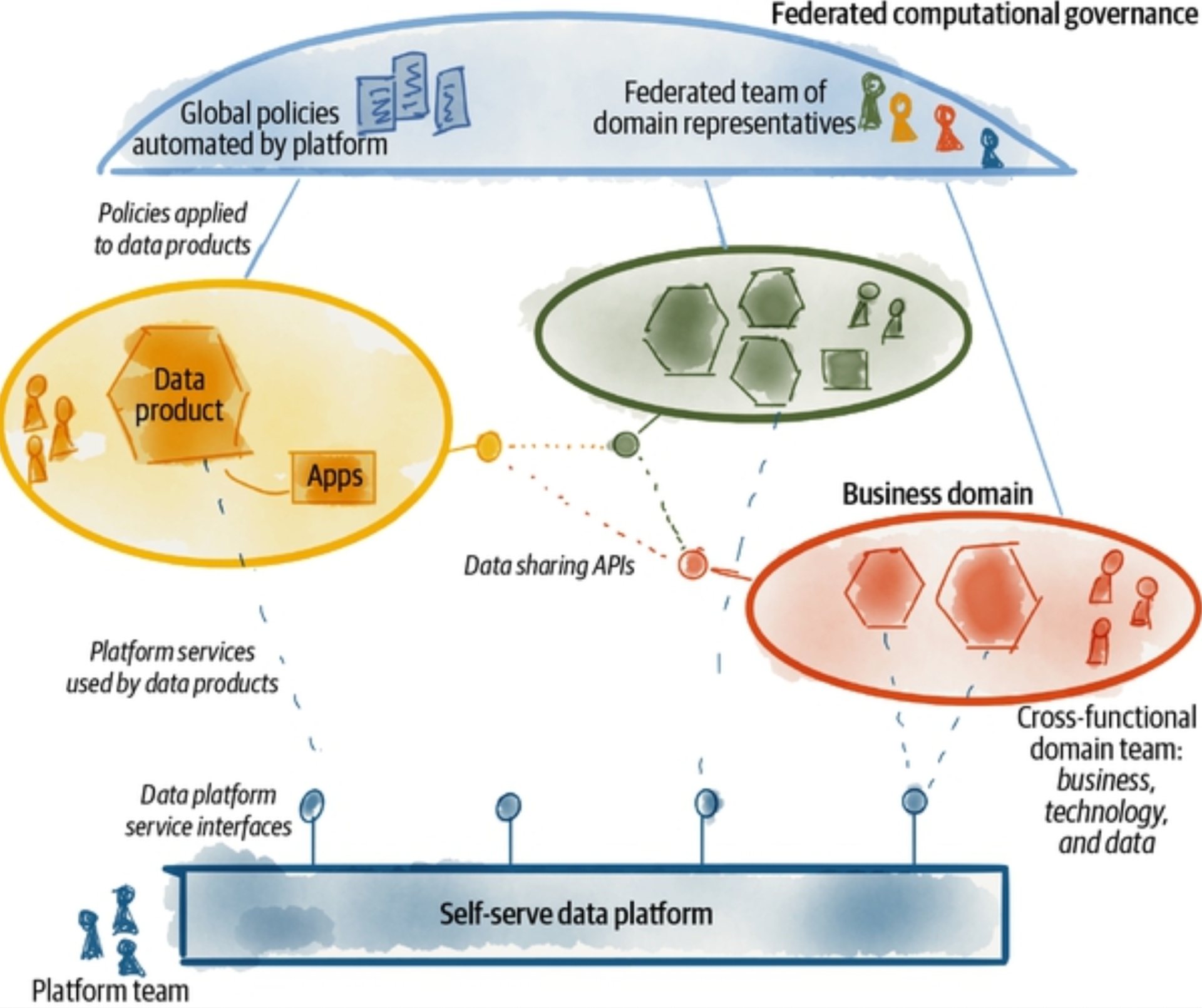
Data Mesh
The data mesh is a recent response to sprawling monolithic data platforms, such as centralized data lakes and data warehouses, and “the great divide of data,” wherein the landscape is divided between operational data and analytical data.24 The data mesh attempts to invert the challenges of centralized data architecture, taking the concepts of domain-driven design (commonly used in software architectures) and applying them to data architecture. Because the data mesh has captured much recent attention, you should be aware of it.
In order to decentralize the monolithic data platform, we need to reverse how we think about data, its locality, and ownership. Instead of flowing the data from domains into a centrally owned data lake or platform, domains need to host and serve their domain datasets in an easily consumable way.
Dehghani later identified four key components of the data mesh:
- Domain-oriented decentralized data ownership and architecture
- Data as a product
- Self-serve data infrastructure as a platform
- Federated computational governance
Other Data Architecture Examples
Data architectures have countless other variations, such as data fabric, data hub, scaled architecture, metadata-first architecture, event-driven architecture, live data stack, and many more.
Who's Involved with Designing a Data Architecture
Bigger companies may still employ data architects, but those architects will need to be heavily in tune and current with the state of technology and data. Gone are the days of ivory tower data architecture. In the past, architecture was largely orthogonal to engineering. We expect this distinction will disappear as data engineering, and engineering in general, quickly evolves, becoming more agile, with less separation between engineering and architecture. When designing architecture, you’ll work alongside business stakeholders to evaluate trade-offs. What are the trade-offs inherent in adopting a cloud data warehouse versus a data lake? What are the trade-offs of various cloud platforms? When might a unified batch/streaming framework (Beam, Flink) be an appropriate choice? Studying these choices in the abstract will prepare you to make concrete, valuable decisions.



