Building an ETL tool with Rust
Creating a simple CSV to parquet pipeline using Rust and Polars


Introduction
Today we will be implementing a very simplistic Rust script that will take a local CSV and write it out to a parquet file. While I know this doesn't seem like a very complex data engineering project, I want us to get the basics of using Rust down and also to get a quick win that will hopefully keep readers engaged. While you don't need to be a Rust expert to follow along, it may help to be somewhat familiar with Rust basics. You can always refer to my other site Rusty Cloud for some basics, but it is still a work in progress, so feel free to also take a look at the fundamental Rust book that got me started The Rust Programming Language.
Moving forward, I will assume that you have Rust installed, and if not please install it by using this link.
Getting Started
Let's hit the ground running and get our project started! The CSV file that we will be using is located on Kaggle.
Lets create a new project called csv_extracor by running the following command in your command line:
cargo new csv_extractor
You should see a folder layout similar to the following:
There are several other options when running cargo new like defining --lib or --bin and many others that would be more useful for larger projects, but we won't go into detail here.
Polars
Polars is a Rust based package that makes it easy to read and write common types of data formats from one source to another. Polars can process larger than memory datasets at blazingly fast speeds. Polars also allows us to use lazy and eager dataframes. These terms will become important later when we decide when we want to process our datasets.
While we could try to implement our own Rust crates from the ground up. This would take a significant amount of time and I strongly believe in standing on the shoulder of giants to get the most value out of your work.
Polars also has a python API in addition to its Rust API. I plan on also doing a data engineering series that uses python to build pipelines with Polars as the backbone. You may ask, "If Polars has a Python API, why even bother with Rust?" Mainly because we will not be implementing our entire ETL program in Polars, and even if we do, Rust makes parallel and asynchronous less of a headache than other programming language (including Python). So we may only see Rust give us 2-5x speed over Python in this example, but if we were to run multiple CSV reads in parallel, the throughput for Rust over Python starts to become exponentially significant.
For now, please visit the following references for Polars if you feel that you are getting stuck or want to experiment more:
Let's add polars to our rust project by typing the following in the command line:
cargo add polars
We can also add specific features in Polars by using the --features or -F flags. While you might be tempted to just say "add all features" this can significantly increase compile times. It's best to just choose the bare minimum.
Lets add the serde, csv, and parquet features to polars with:
cargo add polars -F serde,csv,parquet
Now that we have everything setup, lets get programming!
Reading in the CSV File
Go ahead and delete the "Hello World" boiler plate from you main.rs file under your src folder in your project.
After looking at the Polars guide, lets write a read_csv function that takes a couple inputs and reads a CSV into a Polars Dataframe.
// Import Error from Rust's std library, this will help give us generic errors
use std::error::Error
// Import the Polars prelude which will have a lot of the functionality we are looking for
use polars::prelude::*;
// Now we write a function that takes the CSV path and creates a polars dataframe
// Our function `Result` will either be a DataFrame if everything succeeds or a Standard Error if it fails
fn read_csv(path: &str) -> Result<DataFrame, Box<dyn Error>> {
// Use the polars `CsvReader` to read the CSV path
let df = CsvReader::from_path(path)
// The polars documentation will tell you to use `unwrap`
// here, but I like giving myself more custom error messages
// if this part fails, it is because there is a problem with reading the csv path
.expect("There was an error reading the path")
// tell the operation to finish
.finish()
// If there is an error here, it is because polars
// can't convert the CSV into a Dataframe
.expect("There is an issue converting to a Dataframe");
}
Awesome! We now have a function that takes a CSV path and creates a Polars Dataframe. Lets test it pout in pur main function.
//... Code from function we created above
fn main() {
// notice, you do not have to define the type `:&str` as Rust
// will do that for you on compilation, but it is
// good practice
let read_path: &str = "./linkedin_job_postings.csv";
// use our read function
let df: DataFrame = read_csv(&read_path)
// We need to 'unwrap' our return value
// since it is a 'Result', we can do this with
// `.unwrap()`, but I like giving a message
// so I am using `.expect()` instead
.expect("Failed to create Polars DataFrame");
// Print the results
println!("{:?}", df);
}
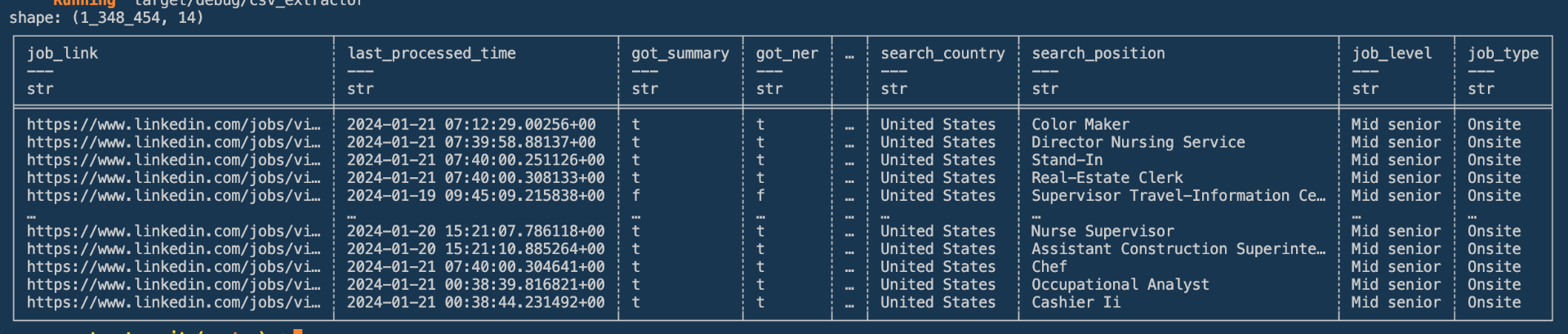
You should see something like the following when you run the following in the command line:
cargo run
Writing to Parquet
If I have a rule of thumb for Data Engineering, it is "write structured data to parquet". Parquet is a highly compressed file format that ships in the file with its schema. That means parquet might split its data contents across 10 files and each file has its self contained schema. This makes "scans" super efficient if you split your parquet, say by update_date because you only have to look in the folder names that are relevant to your update_date filter. You can essentially use your file path naming convention as your index.
So lets write our 500mb CSV file to parquet and see how much space we can save. We won't worry about taking advantage partitioning our csv file right now, but will take a look in a future post.
Underneath our read_csv function but above our main lets create the write_parquet function.
// ...Read CSV function above
// our function takes 2 arguments, the dataframe we want to write and where to write
// Our function returns either nothing and frees the dataframe from memory after it writes it to parquet, or returns an error
fn write_parquet(mut df: DataFrame, write_path: &str) -> Result<(), Box<dyn Error>> {
// create the file that we will write our dataframe to parquet
// we prefix with `mut` because we want the filke to be mutable, which means we can change the data in memory
let mut file = std::fs::File::create(write_path).expect("Error creating file path");
// write to the mutable `file` our mutable dataframe
ParquetWriter::new(&mut file).finish(&mut df).expect("Error writing to file");
// If all goes `Ok`, return nothing and free the dataframe from memory
Ok(())
}
// Main function below...
Putting it all together
Now that we have a function to read a CSV and a function to write to parquet. Lets put it together.
// ... Our read and write functions are above
fn main() {
let read_path: &str = "./linkedin_job_postings.csv";
let df: DataFrame = read_csv(&read_path)
.expect("Failed to create Polars DataFrame");;
println!("{:?}", &df);
// define our path we wnt to write our parquet to
let write_path: &str = "./linkedin_job_postings.parquet";
// if you don't need to return anything to a variable
// Rust has a shorthand to help it understand thats what
// you want to do by using `let _ = ` with the `_` being
// the variable name
let _ = write_parquet(df, &write_path)
.expect("Unable to write to parquet");
}
You can run the following in your command line in order to compile your Rust code:
## For Debug
cargo build
## Or for release
cargo build --release
Once you have compiled your code with the cargo build tooling, you can run it by doing the following
## for debug build
./target/debug/csv_extractor
## for release build
./target/release/csv_extractor
Conclusion
Congrats, you can now use Rust to run a simplistic CSV to parquet data pipeline. While this may seem trivial lets think about this from a enterprise perspective. I have written the equivalent pipeline using Pandas, and we can see the time difference between the two.
import pandas as pd
df = pd.read_csv('./linkedin_job_postings.csv')
print(df)
df.to_parquet('df.parquet.gzip', compression='gzip')
Pandas
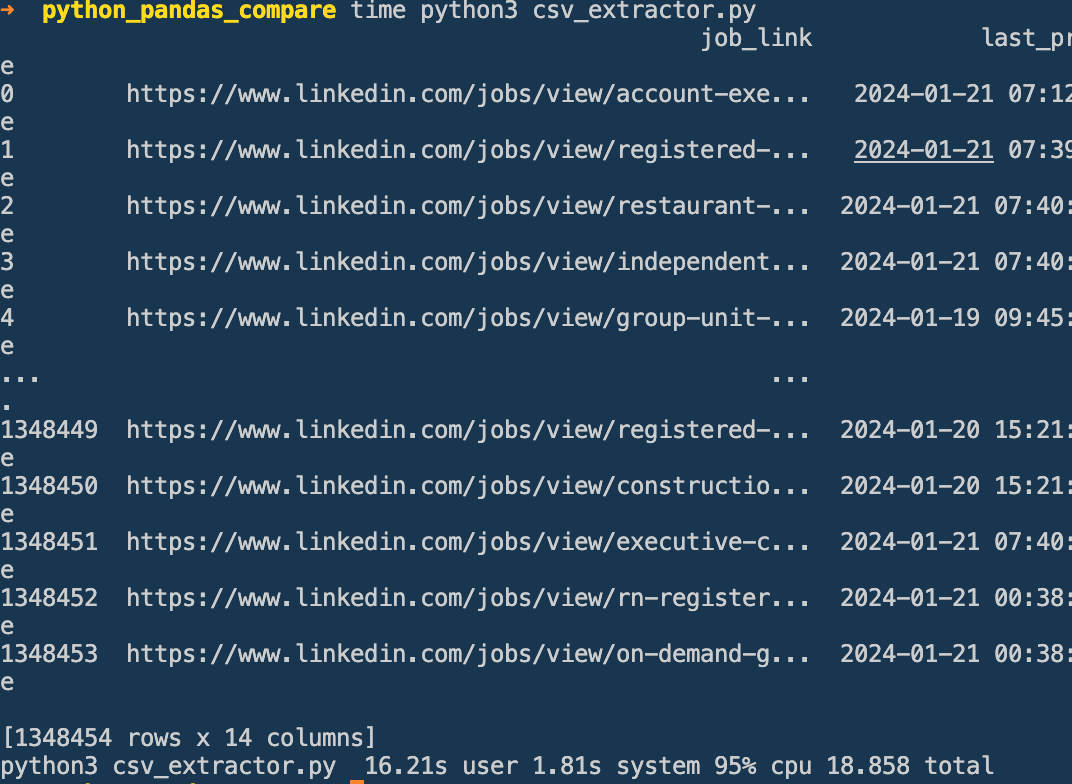
The pipeline took 16.21s from the User perspective and 18.8s total. And lets look at the Rust equivalent.
Rust
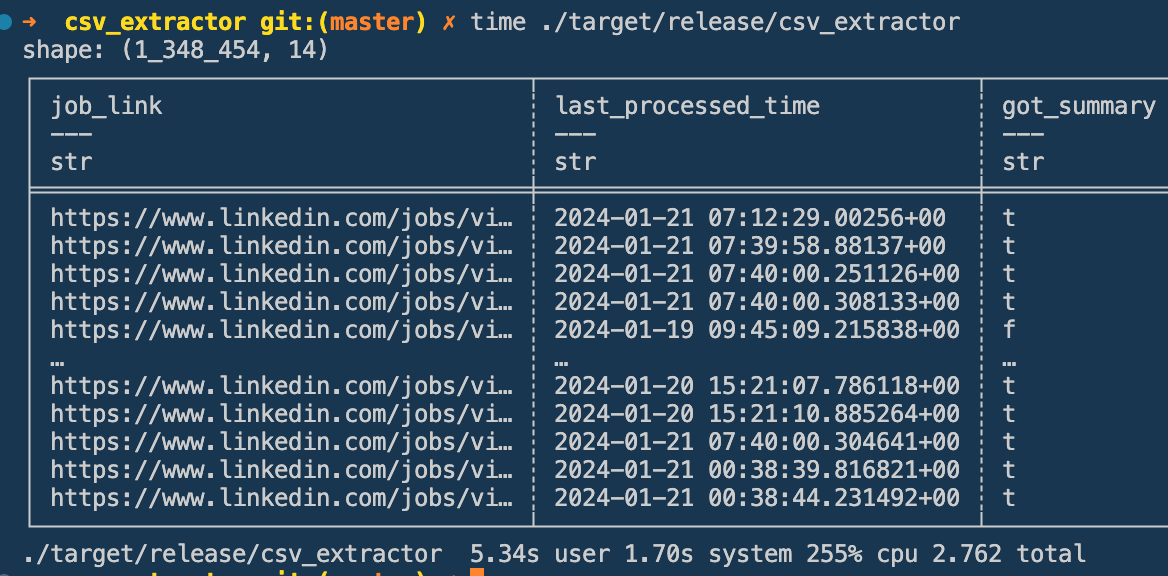
Rust only took 5.34s from the User perspective and only 2.7s total!
Rust is almost 6x faster! Now, if we consider how easy it is to use channels and async with tokio in Rust, we can see double digit multipliers in speed!
One thing I will say is that it is much easier to write in Python. Look at the code difference between my Python script and my Rust program. What I did in 20 lines of Rust only took me 4 lines in Python, and given that Polars has a Python API why should we still use Rust? For me it's a couple simple reasons:
- Package management with Cargo is so easy you feel like you are being tricked
- Easy multi-threaded processing with Rust's
stdlibrary usingmpsc - Easy async programming with
tokio - No slow down in long running data pipelines because of garbage collection
- Easy multi-target compilation
- WASM capability (I believe that this will be a game changer for data security in the future)
While I did not get to show off some of this functionality in this post, I have used it with great success before. I was able to take a Python pipeline that took 8 hours to run and wrote a Rust program that did it in 4 minutes using tokio and mpsc to aggregate data from 15,000 REST api endpoints.
I hope to see you in the next post!



